
通过阅读其他的关于LSI关键词的文章你会发现下面这两点:
- 谷歌通过一个叫做LSI的技术来索引页面。
- 在内容中使用LSI关键词可以让网站在谷歌排名更高。.
这两种结论其实都是错误的。
在本篇指南中会告诉你其中的原因,以及你应该做些什么。
但是,先从基础开始…
什么是LSI关键词?
LSI关键词指的是谷歌判断和某个话题语义相关的词——这也是大部分SEO社区中所认为的。如果你的话题是关于 cars(汽车),那么它的LSI关键词就是 automobile(自动化), engine(引擎), road(道路), tires(轮胎), vehicle(车辆),以及 automatic transmission(自动档)。
但是根据谷歌 John Mueller 的话来说,LSI关键词并不存在:
There’s no such thing as LSI keywords — anyone who’s telling you otherwise is mistaken, sorry.
— ? John ? (@JohnMu) July 30, 2019
所以到底是怎么回事?
在我们回答这个问题之前,你需要对 LSI 做更多的了解。
什么是LSI?
Latent Semantic Indexing (LSI、潜在语义索引) 、或者是 Latent Semantic Analysis (LSA、潜在语义分析)是1980年发明的一种自然语言处理技术。
不幸的是,除非你对一些专业的数学术语(诸如:eigenvalues(特征值), vectors(向量), single value decomposition(单值分解)等)熟悉的话,否则技术本身是不那么容易理解的。
因此,我们并不会详细讨论LSI的工作原理。
相应的,我们会专注解决已经出现的问题。
下面是LSI的发明者对该问题的定义:
搜索者使用的词,通常与搜索信息被索引的词不同。
这个到底是什么意思呢?
打个比方,你现在想知道夏天什么时候结束、秋天什么时候开始。但是现在你的WiFi没办法用。所以你回到学校,找到了一本百科全书。与其一页一页的翻找,你会在目录索引中查找 “fall(秋天)”,然后再翻到对应页面查找相关内容。
下面就是你会看到的内容:

很显然,这个并不是你想找的。
译者注:英文 “Fall”有秋天的意思,同时也有跌落、滑落的意思。
但是你并没有灰心,你回到索引目录,这才发现你想找的内容是在 “Autumn(秋天)“里——另外一个秋天的叫法。

这里的问题是,“Fall”这个词是一个同义词,也是个多义词。
什么是同义词?
同义词指的是一个词或者词组和另外一个词或词组有着相近的含义。
例如 rich 和 wealthy,Fall 和 Autumn,以及 cars 和 automobiles
根据LSI的专利说明来看,这就是为什么同义词经常会产生一些问题:
[…] 人们用来描述同一对象或概念的词语时有极大的多样性;这称为同义词。处于不同上下文、认知不同、或者是语言习惯不同的用户,会用不同的方式描述同一个信息。例如一个已经被证实的例子,任意两个人针对单一一个大家都熟知的物体进行描述时,使用相同词汇描述该物体的平均概率是低于20%的。
但是这和搜索引擎又有什么关系呢?
想象一下,现在我们有两个页面是关于汽车的。两个页面几乎是一样的,但是一个页面描述汽车时,使用的是 “cars” ,而另外一个使用的是 “automobile”。
如果我们使用的是一个非常原始的搜索引擎,只能索引页面上出现的词或词组的话,当我们搜索“cars” 的时候,那么这两个页面只会出现其中一个结果。
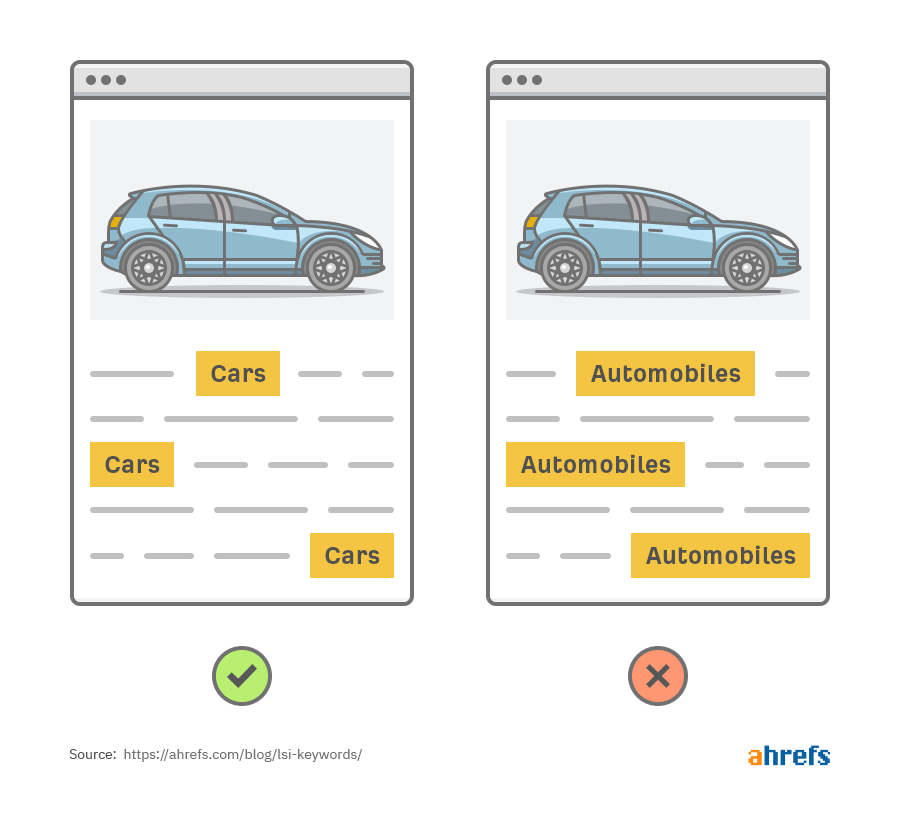
这个很糟糕,因为这两个页面是非常相近的;只是表达方式上有所不同而已。甚至使用 “automobile” 的页面相比于使用 “cars” 的页面会更加专业一些。
底线:搜索引擎需要去理解这些同义词,以便于给用户返回最好的结果。
什么是多义词?
多义词指的是一个词或词组具有多个含义。
例如 mouse 有 rodent / computer 的含义、bank 有 financial institute / riverbank 的含义、以及 bright 有 light 和 intelligent 的含义。
译者注:mouse:老鼠 / 鼠标、bank:银行 / 河岸、bright:光明 / 聪明。
根据发明LSI的人所说,它会有这样的问题:
在不同的上下文、或者阐述的人不同时,使用相同的词或词组会有截然不同的含义(例如 Bank可以表示河岸、也可以表示银行)。因此如果在搜索中只是匹配一个词或是它的同义词有可能无法满足真正的搜索需求。
这些词给搜索引擎带来了和同义词相同的问题。
比如,如果我们搜索 “apple computer(苹果电脑)”,原始的搜索引擎可能会返回下面两个结果,但很显然其中有一个并不是我们想要的:
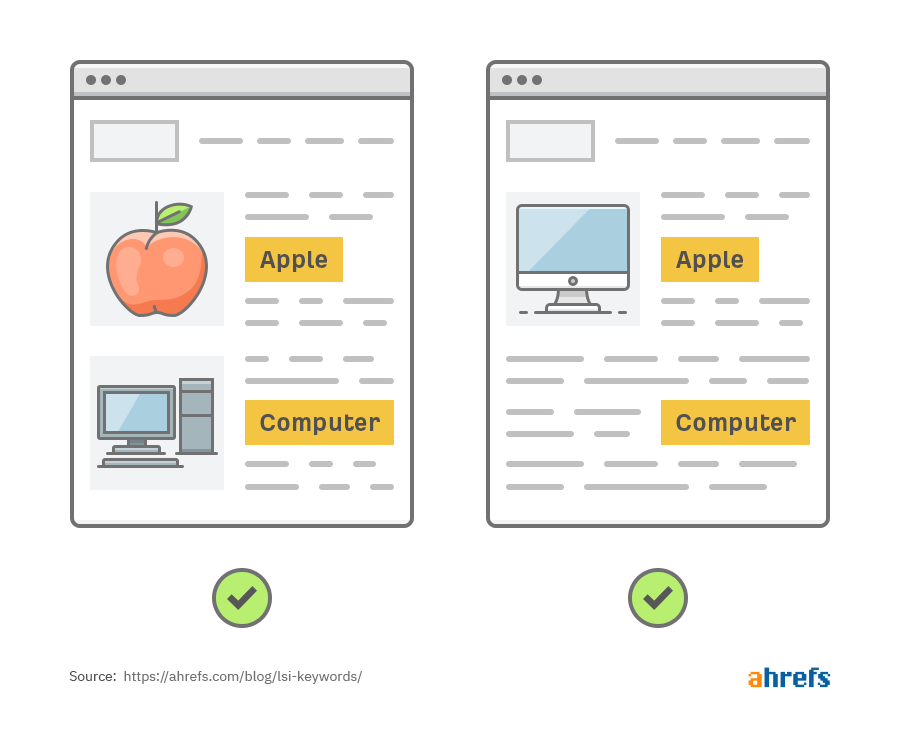
底线:如果搜索引擎无法理解多义词的含义,那么它们可能会返回不相关的结果。
LSI的工作原理是什么
机器是非常死板的。
它们无法理解单词之间的关系,这和我们人类不一样。
举个例子,大家都知道 big 和 large 的含义是一样的。同时大家也知道 John Lennon 是 The Beatles的一员。
译者注: The Beatles:披头士乐队,是1960年在利物浦组建的一支英国摇滚乐队。John Lennon:约翰·温斯顿·列侬,摇滚乐队“披头士”的成员。
但是如果你不告诉机器,它是无法理解这些的。
问题是,我们没有办法把所有的信息都告诉机器,这会消耗大量的时间和精力。
LSI就解决了这样的问题,它通过复杂的数学模型从一系列文档中获取词和词组之间的关系。
简单来说,如果我们针对和季节相关的文件进行潜在语义分析之后,机器就可以得出下方这些结果:
首先,“Fall”和 “Autumn” 是同义词:
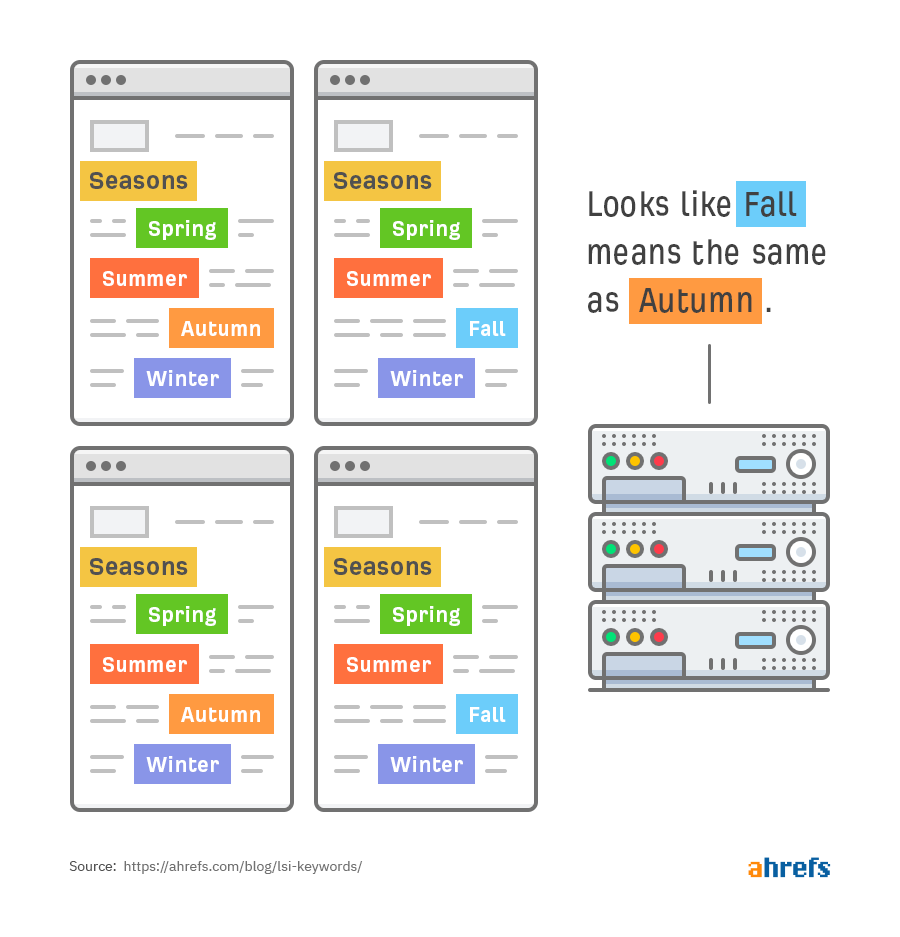
第二,例如 Season、Summer、Winter、Fall、以及 Spring 在语义上是有联系的:
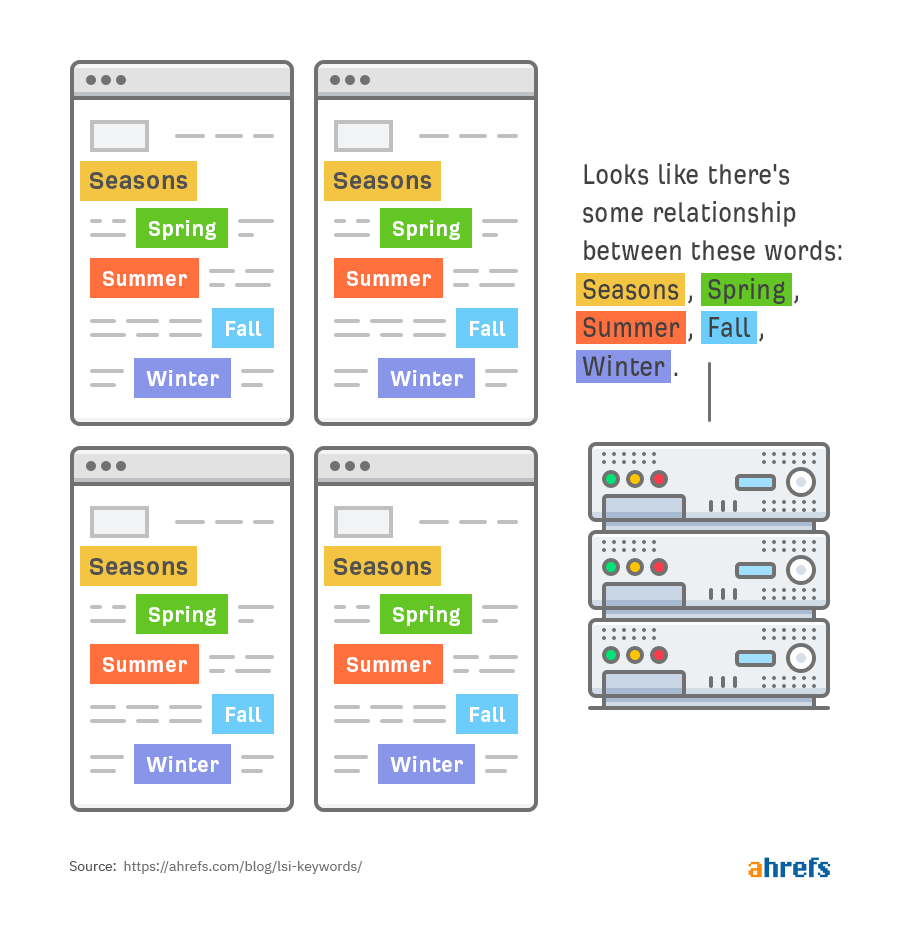
第三,Fall 是一个多义词,它会和两个不同系列的词联系在一起:
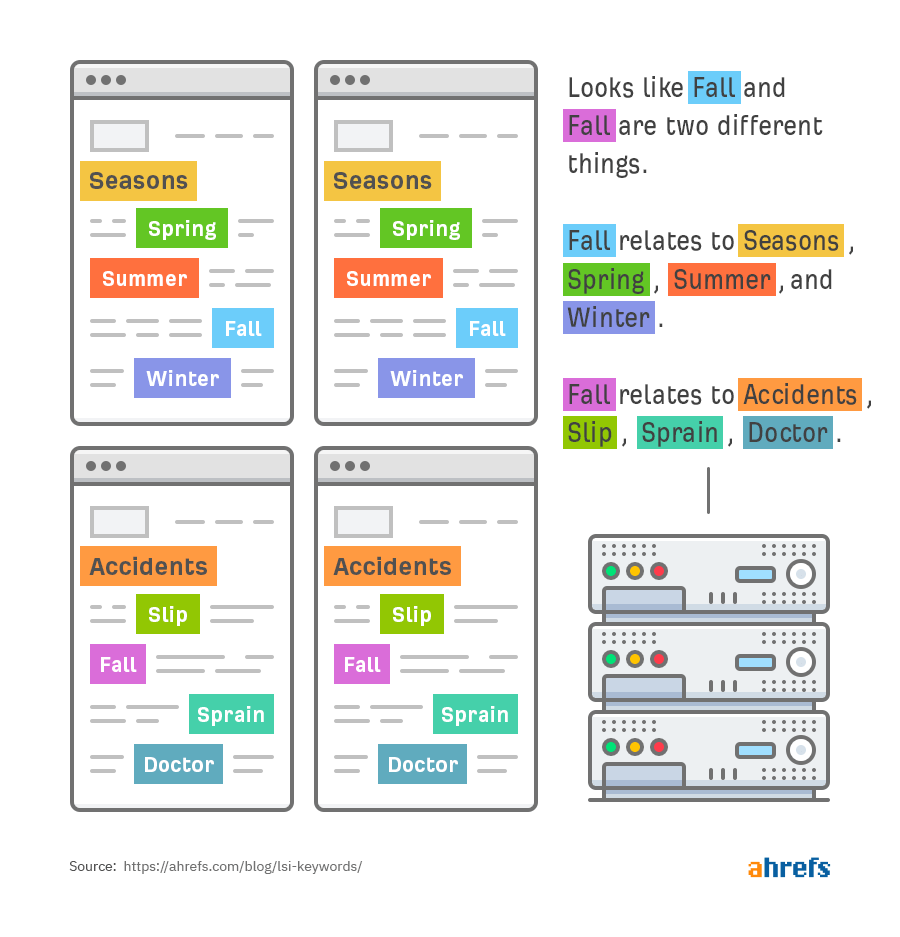
搜索引擎可以使用这些信息来进行精确的搜索匹配,并提供更为相关的搜索结果。
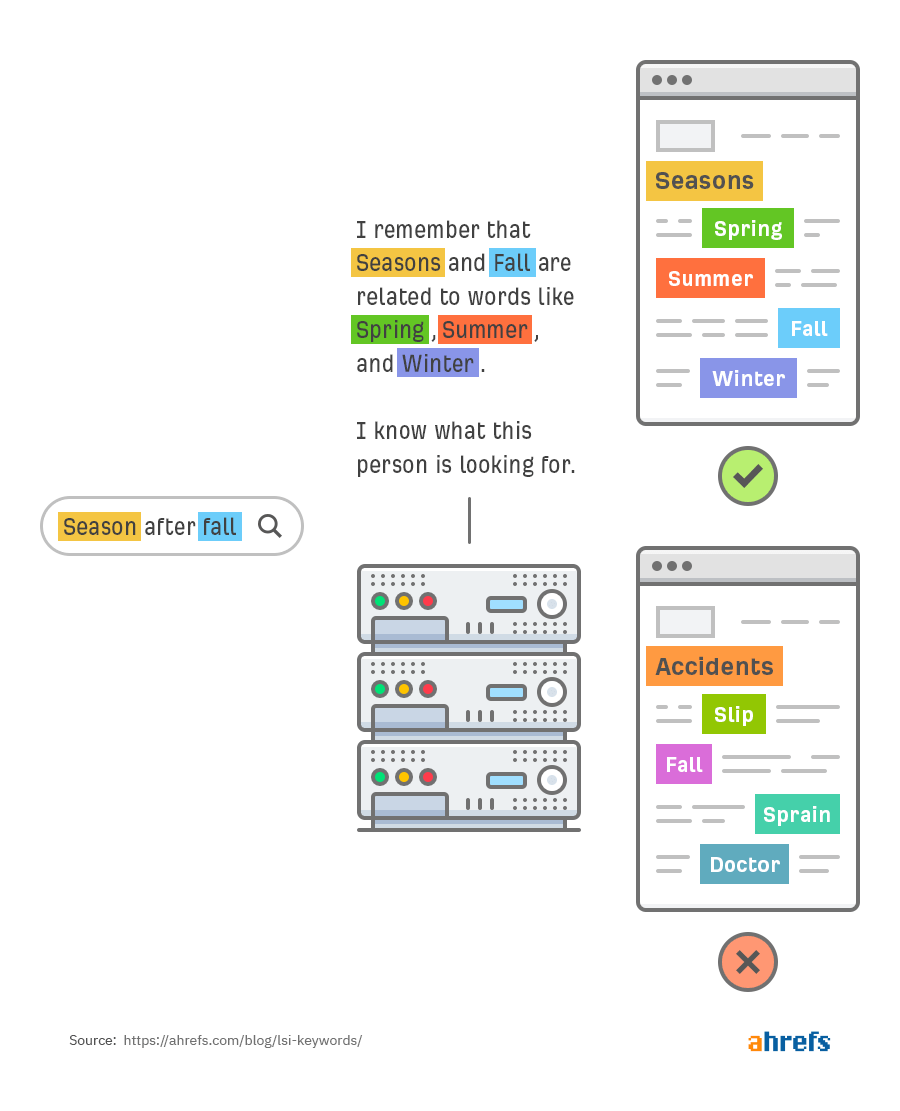
谷歌使用LSI吗?
看过上方内容,就会知道为什么人们一直都猜测谷歌在使用LSI的技术。毕竟只进行单词匹配,返回的结果可能是无法满足搜索需求的。
同时,我们通过很多情况可以看到谷歌是可以理解同义词的:
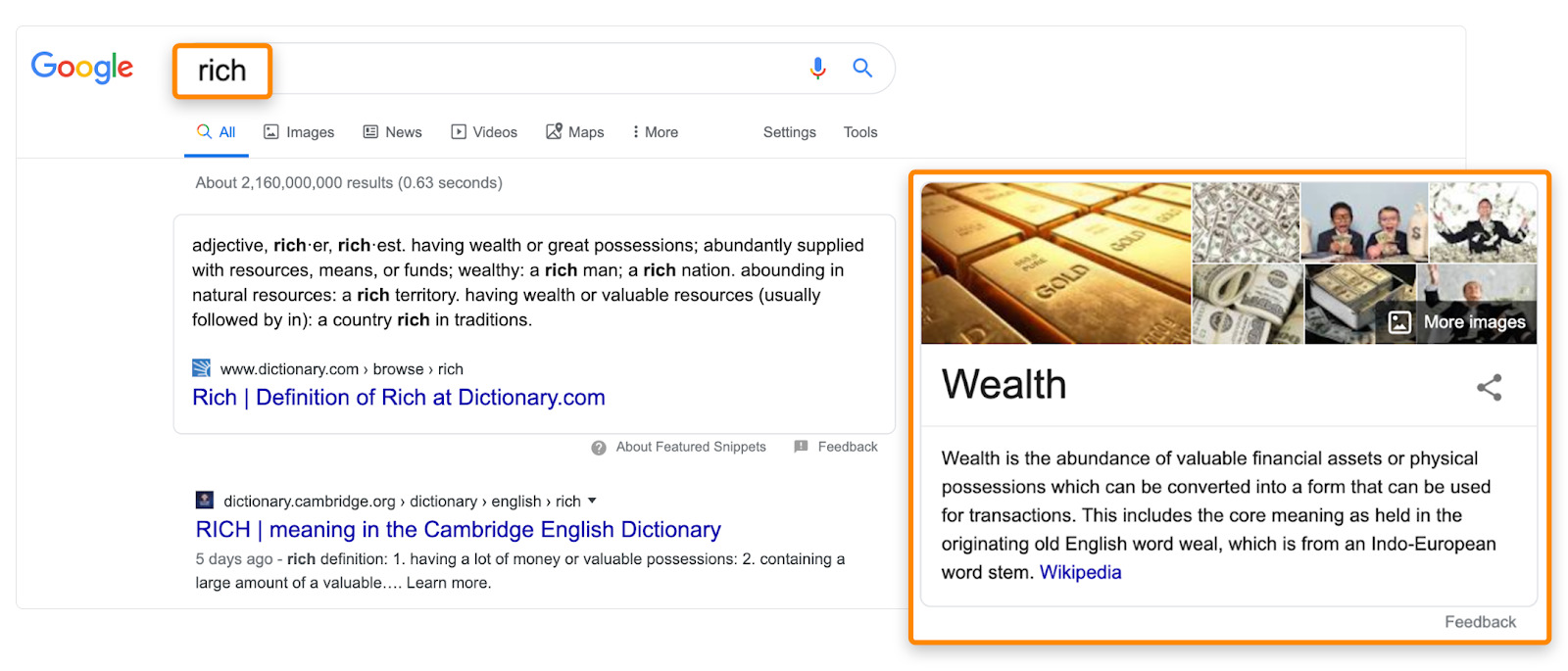
以及多义词:
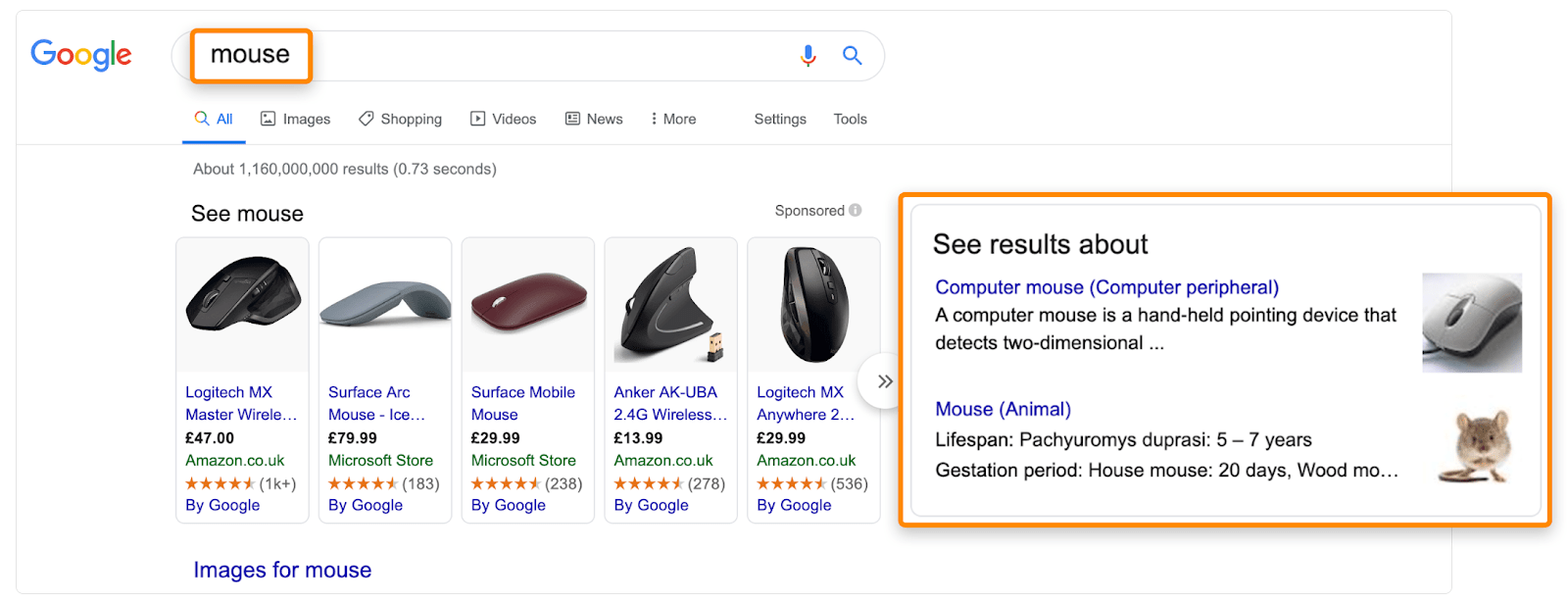
但是尽管如此,谷歌几乎可以肯定不使用LSI技术。
我们为何知道?应为谷歌的发言人是这么说的。
不相信它们?
下面是可以支持这个观点的三个证据:
1. LSI是一个过时的技术
LSI是1980年代发明的技术,远早于世界互联网的发明。因此,从来没有打算将其应用于体量庞大的文档中。
因此,谷歌开发了更好的、更具可扩展性的技术来解决相同的问题。
这里 Bill Slawski 说的很好:
LSI技术的发明并不是用于处理网络数据的 […] 谷歌创造了一个词向量方法(使用在RankBrain上)它更现代、体量更大、同时还适用于处理网络数据。在这个可以使用词向量方法的时候,你却还在用LSI技术,就好比用卡丁车参加法拉利的比赛。
2. LSI是用于索引已存在的文档的
世界互连网不仅仅很大,同时也是不断在变化的。
意思是,在谷歌的索引库中,有几十亿的页面数据会经常性的变动。
这就是一个问题,因为LSI的专利告诉我们,每次文档发生巨大变动时,都需做一次完整的分析。
这就意味着需要非常强的处理能力。
3. LSI是一个专利技术
Latent Semantic Indexing (LSI、潜在语义索引) 专利 在1989年授予给了 Bell Communications Research, Inc的Susan Dumais。她是这项技术的共同发明人之一,之后在1997年加入了微软,并从事与搜索相关的创新工作。
在美国,专利是在20年后到期,这意味着LSI专利在2008年到期。
谷歌早在2008之前就能够返回非常相关的内容,因此这又是另一证据,表明谷歌是不使用LSI的。
再一次,这里,Bill Slawski 说的非常好:
谷歌确实尝试索引单词的同义词以及其他的含义。但是它并没有使用LSI技术来做到这一点。称其为LSI会误导用户。 谷歌至少从2003年开始就提供同义词的处理和基于同义词的搜索优化。谷歌没有必要使用LSI技术,因为这就好像你在用你的手机发电报一样。
大多数SEO人员认为 “LSI关键词” 是一些语义相关的词组或是短语。
我们遵循该定义(尽管在技术上不准确),那么在内容中使用一些语义相关的单词和短语可以肯定是有助于改善SEO的。
为什么是这样?谷歌已经很直接的说明了:
试想一下:如果你搜索 “dogs”,你可能并不想看到一个页面上 “dog” 这个词出现了成百上千次。考虑到这一点,算法会评估页面是否包含 “dog” 以外的其他相关内容,例如狗的图片、视频、甚至是狗品种的列表。
在关于狗的页面上,谷歌会认为各个品种的名称词在语义上都是相关的。
但是,为什么这会对页面参与特定词的排名产生帮助呢?
原因很简单:因为它们可以帮助谷歌更好的理解页面主题及内容。
举个例子,下面是两个包含 “dog” 这个词的页面:
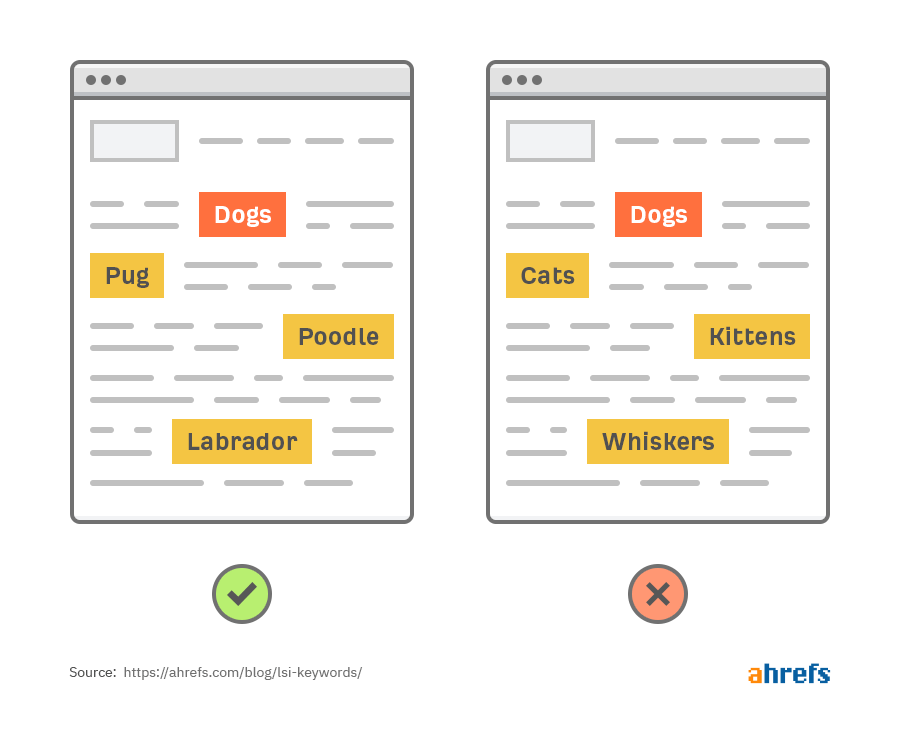
通过上面的两个页面中的重要单词你可以看到,第一个页面是主要关于狗的,而第二个页面主要是关于猫的。
谷歌就是利用这样的信息,对页面进行相关性的排序。
如果你针对一个话题非常的专业,那么自然的你就会将相关联的信息包含在你的内容其中。
举个例子,如果你在写一个关于电子游戏的文章,那么你很难不提到这些词,例如 “PS4 games(PS4 游戏)”、“Call of Duty(使命召唤)” 以及 “Fallout(辐射)”。
但是当你涉及一个复杂的话题时,你很容易就会错过重要的词。
比如,我们关于nofollow链接的指南中就没有提及任何关于赞助链接、以及UGC链接的内容:
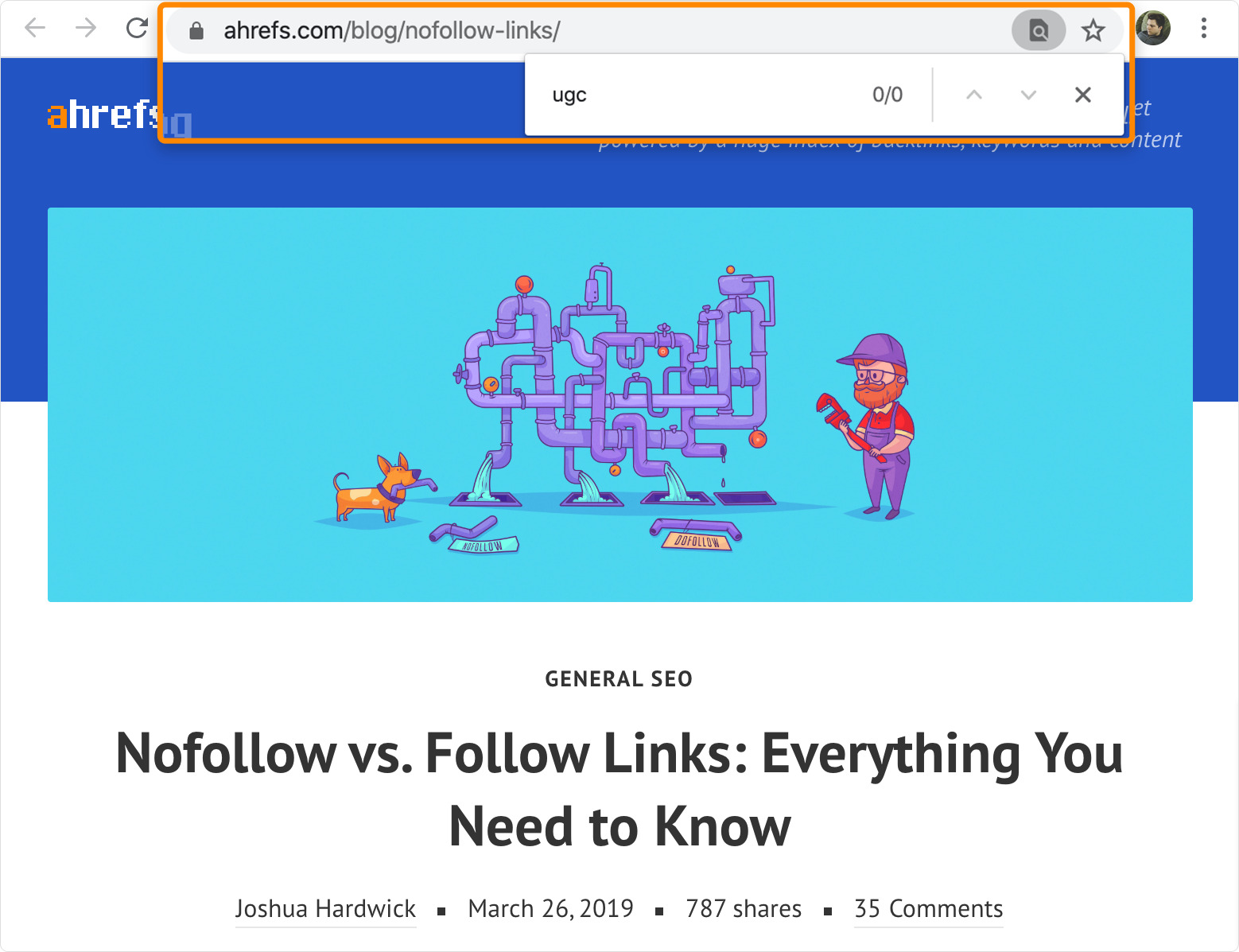
谷歌可能将这些视为语义相关并且是非常重要的词,任何有相关主题且有质量的文章都应提及这些词。
这可能就是为什么,提及这些词的文章排名超过我们。
考虑到这一点,下面有九种方法来查找可能相关联的单词或短语:
1. 使用常识
检查你的页面内容,查看是否有任何遗漏之处。
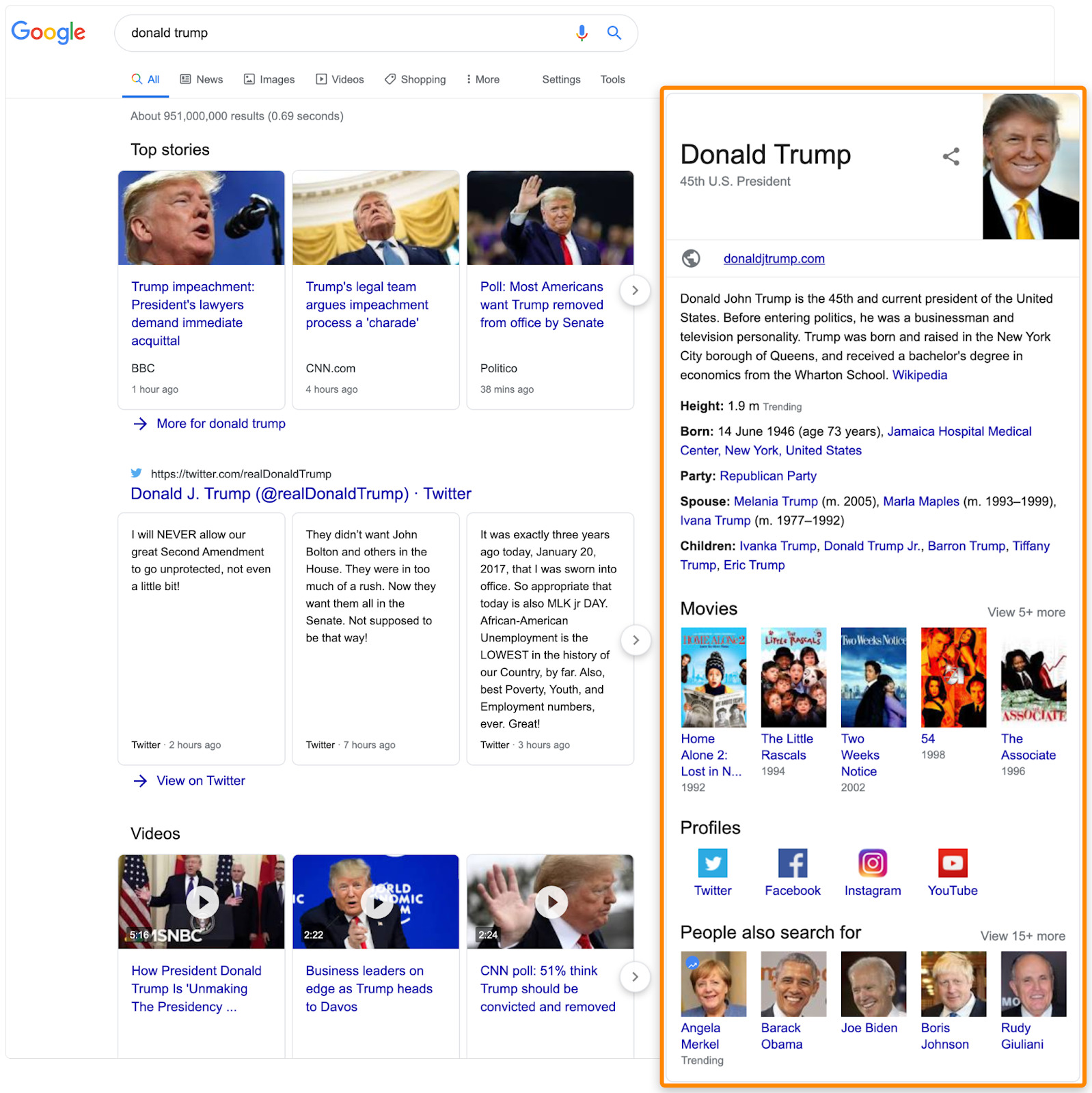
例如,如果该页面是有关 Donald Trump 的传记文章,但没有提及他被弹劾的事情,那么你可能会为此去添加一段介绍。
那么自然的,你就会提及这样的词汇,例如 “Mueller Report(穆勒报告)”、“Nancy Pelosi(南希·佩洛西)”、以及“whistleblower(吹哨人)”。
请记住,我们无法确认谷歌是否将这些单词和短语视为是语义相关的。但是,由于谷歌旨在理解人类固有理解的单词之间的关系,因此使用常识是很正常的。
2. 查看自动填充结果
自动填充功能的结果并不总是会显示重要的相关联词汇,但是它们可以提供一些可能值得一提的内容线索。
例如这些词 “donald trump spouse(特朗普配偶)”、“donald trump age(特朗普年龄)” 、以及 “donald trump twitter(特朗普推特)”。这些都是搜索 “donald trump” 之后自动填充的结果。
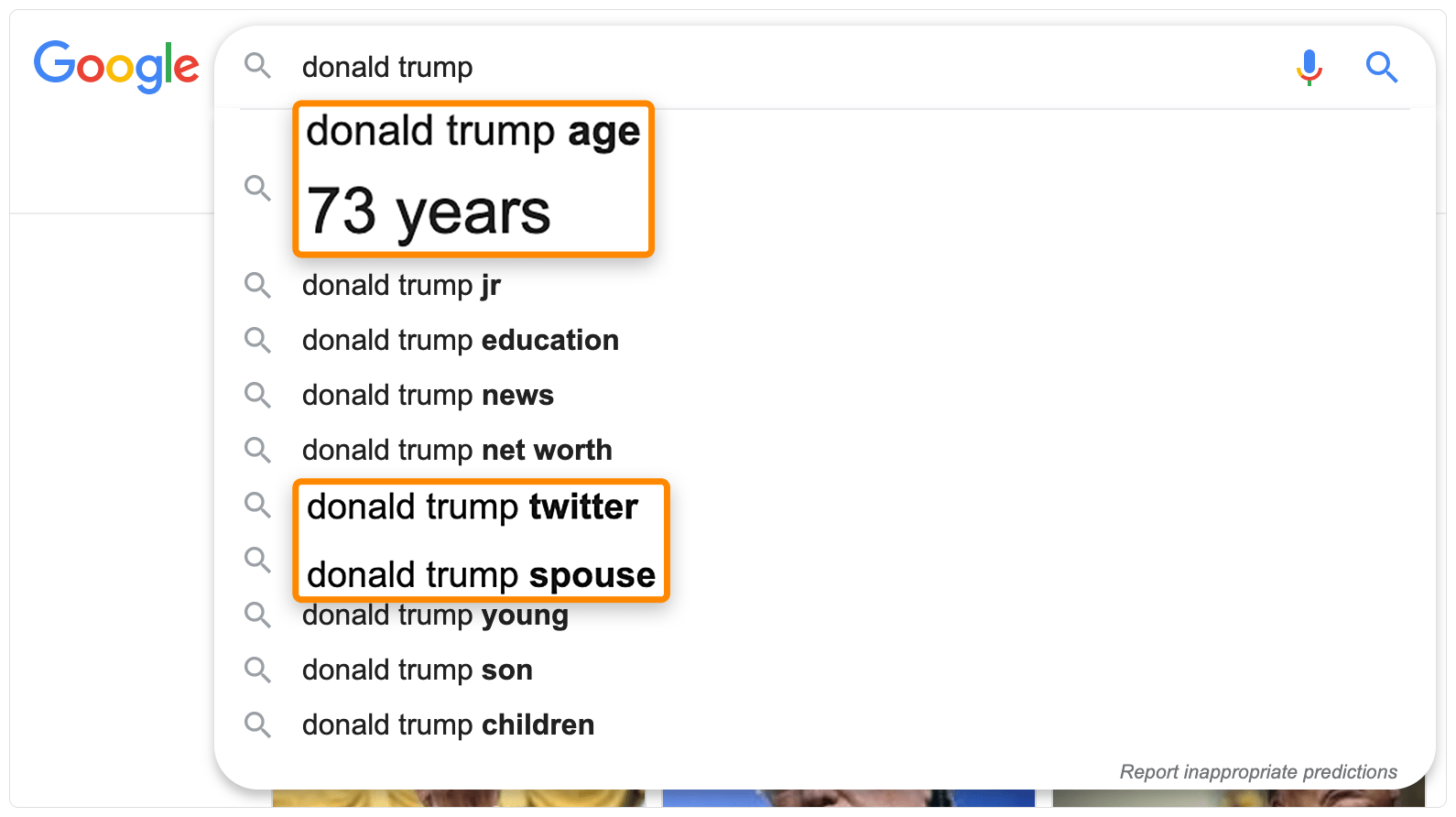
这些词本身并不是有联系的词汇,但是它们所指的东西却是有联系的。上方的例子指的就是这些词 “Melania Trump(梅拉尼娅·特朗普)、73岁、以及 @realDonaldTrump”
如果有关于特朗普的传记文章,那么其中应该提到这些事情,对不对?
3. 查看相关搜索
相关搜索会显示在搜索结果的最底下。
和自动填充的内容一样,它们可以为潜在相关的单词或词组提供一些有价值的线索…
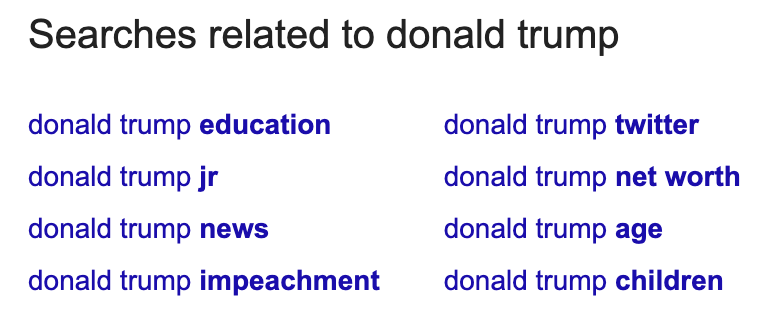
这里,“donald trump education(特朗普学位)” 指的是他加入的 The Wharton School of the University of Pennsylvania(宾夕法尼亚大学沃顿商学院)
4. 使用 “LSI关键词” 工具
一些知名的LSI关键词工具其实和LSI本身没有任何关系。但是,有些时候它们确实可以给出一些不错的建议。
比如,我们输入 “donald trump(特朗普)” ,工具会给出这样的词,例如他的妻子 “Melania Trump” 以及他的儿子 “Barron Trump”。
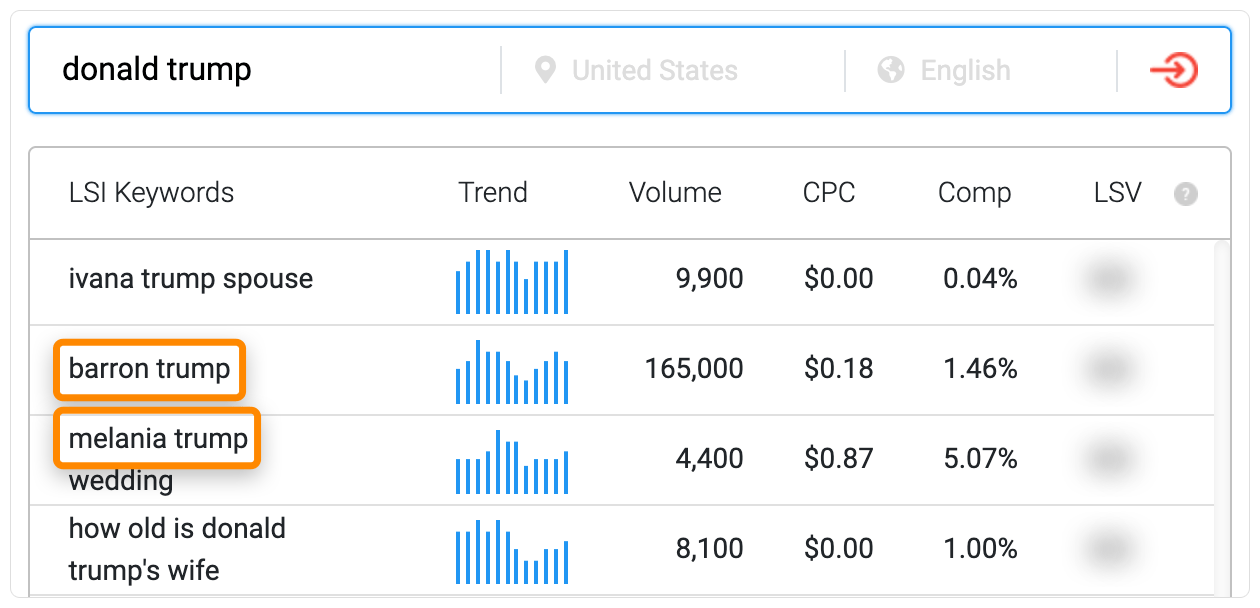
5. 查看排名页面参与排名的其他关键词
使用Ahrefs Keywords Explorer(关键词分析)中的 “Also rank for(同时有排名的词)” 报告去查找可能有联系的单词或者短语。
![]()
如果数据太多你没办法处理的话,试着对排名前三的页面使用Content Gap(内容差距机会)工具去分析,并且记得将交集网站数量设置为“3”。
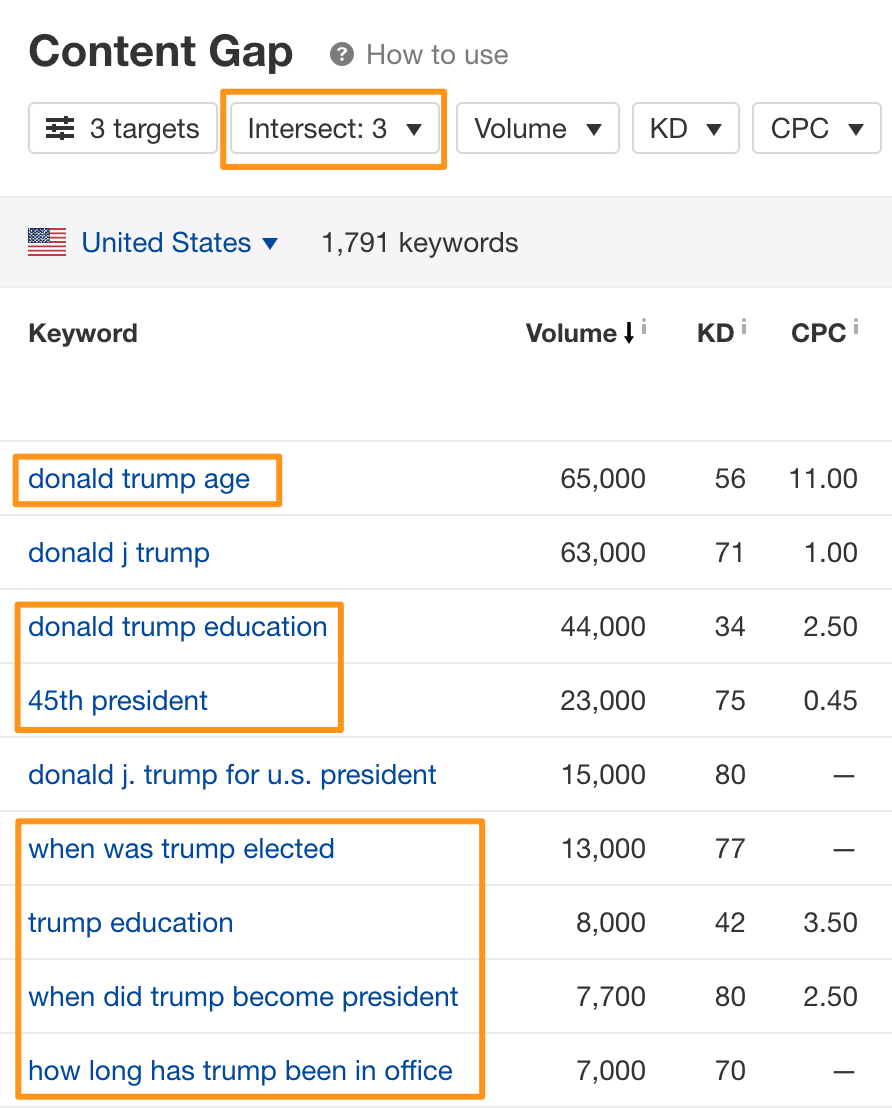
这里显示了所有页面都参与排名的关键词,通常可以为你提供一些关联单词或者短语的线索。
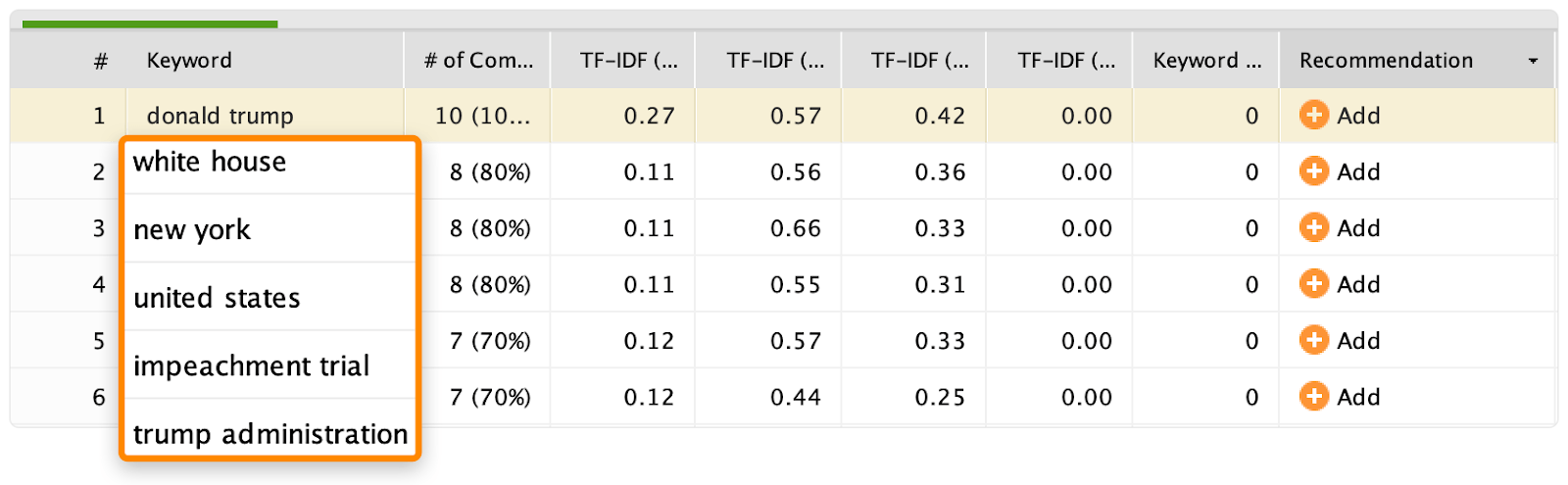
6. 做一个TF*IDF分析
TF-IDF和latent-semantic indexing (LSI、潜在语义索引)以及 latent-semantic analysis (LSA、潜在语义分析)没有任何关系。但是,它可以帮你找到一些你可能丢失的单词或者短语。
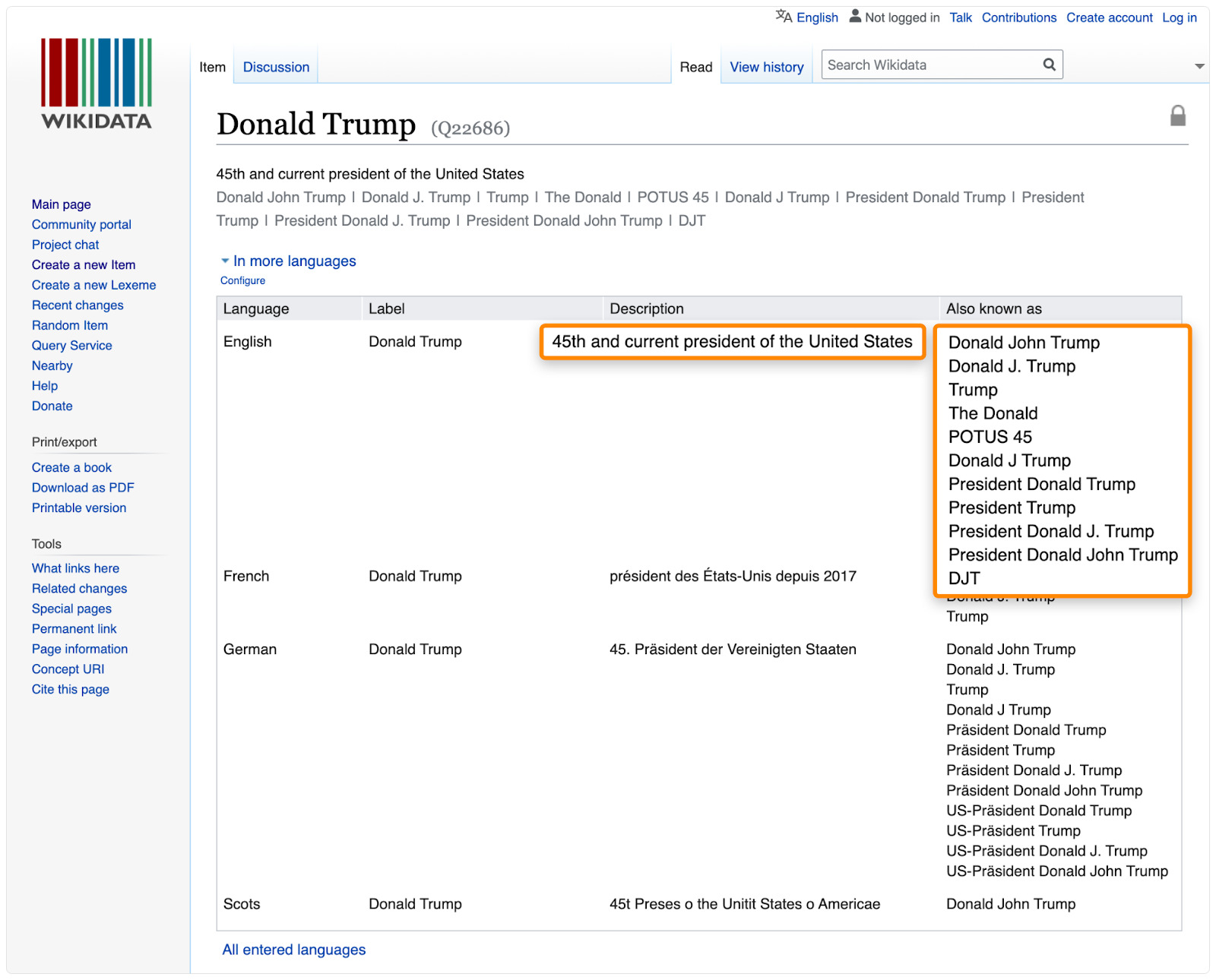
7. 查看知识库
类似像Wikidata.org 以及 Wikipedia这样的知识类网站,通常都可以找到一些有关联的词汇或者短语。
谷歌通常也会从这两个知识类网站获取数据,并展示为知识图。
8. 对知识图进行逆向工程
谷歌在知识图中储存了很多人、时间、以及概念之间的关系。同时,知识图的结果很多也会体现在谷歌的搜索结果中。
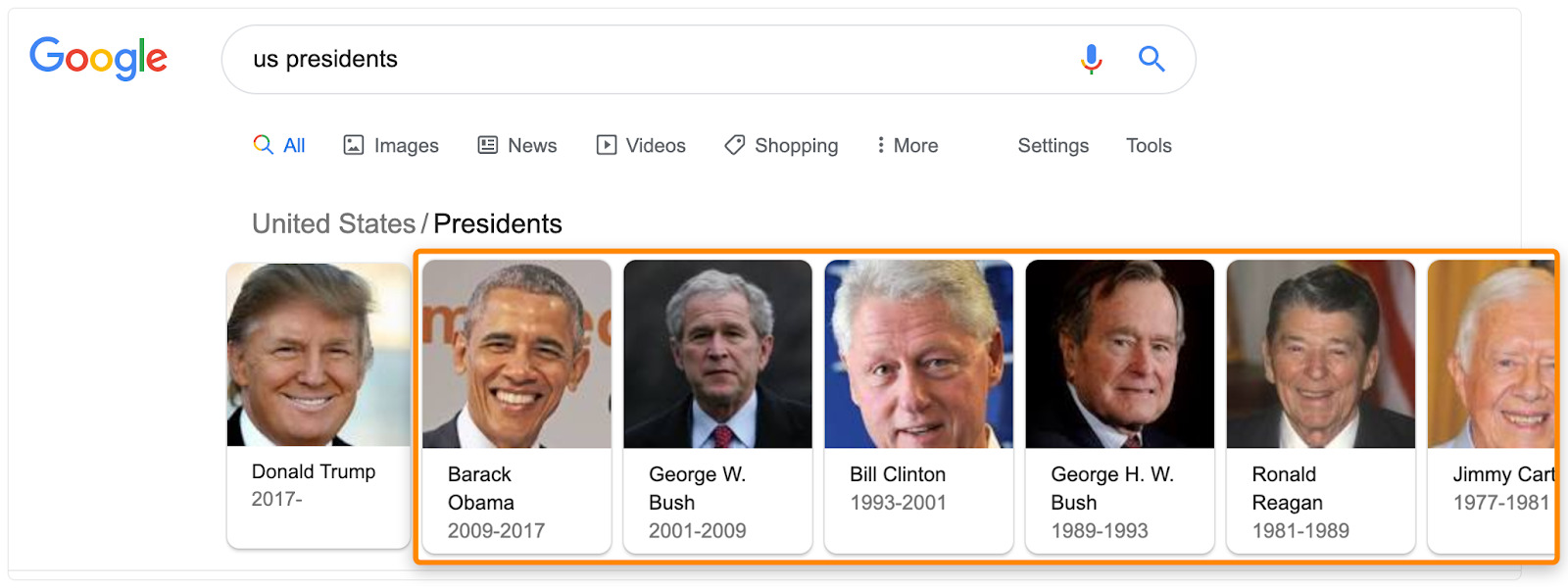
尝试去搜索你的关键词,看看知识图中是否会展示一些额外的信息。
因为这些是谷歌认为与搜索的主题相关联的内容,所以绝对值得在合适的地方加入针对相关联的内容。
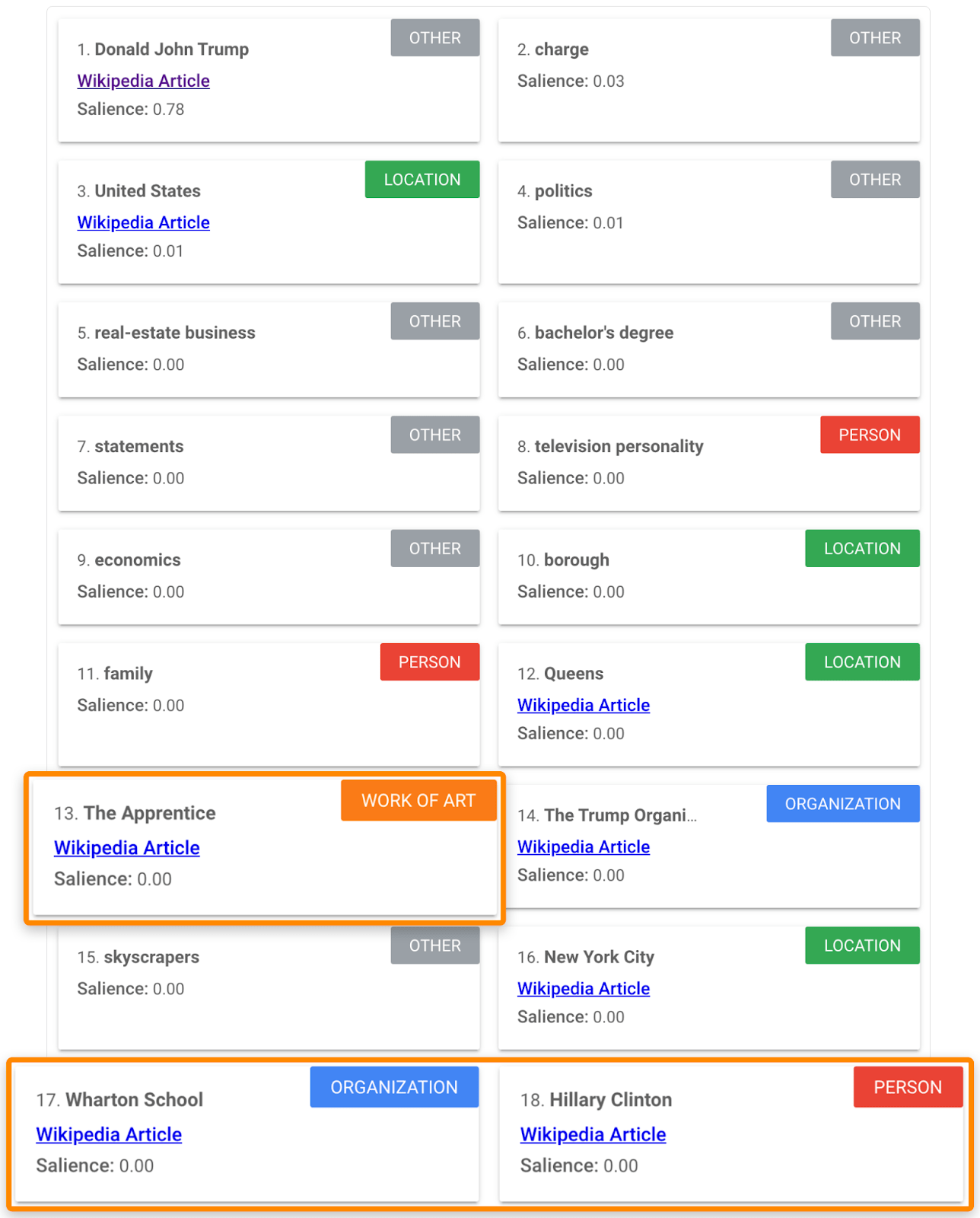
9. 使用Google的自然语言API查找内容
将排名靠前的页面的内容粘贴到Google’s Natural Language API demo(谷歌自然语言处理API测试)中,寻找你可能错过的、但是相关联且很重要的内容。
最后
LSI关键词并不存在,但是语义相关的单词,词组,内容是存在的。它们可以提升网站的排名。
你只需要确保在合适的时候使用它们,但也不要随机的放在某些位置。
因为在一些情况下,如果添加了这个词,意味着你可以要新增加一个段落。
比如,如果你想在一篇关于特朗普的文章中加入 “impeachment(弹劾)” 以及 “House Intelligence Committee(众议院情报委员会)” 这些词的话,你可以就需要针对这些去多创作一些新的段落和题目。
文章为作者独立观点,不代表站长派立场,本文链接:https://zhanzhangpai.com/?p=532
免责声明:本站部分内容来源互联网整理,如有侵权请联系站长删除。站长邮箱:1245911050@qq.com









